
Bonjour aujourd'hui je vais vous présenter un tutoriel sur une des fonctionnalités qui étaient une des plus attendues de la version 4.14 de l'ArcGIS API for JavaScript : le clustering.

C'est quoi le clustering ?
Comme présenté dans mon article détaillant les nouveautés de la 4.14, le clustering est une méthode , encore en béta, qui permet de rassembler plusieurs entités spatiales en un groupe de points, appelé cluster, basé sur une zone d'influence ou clusterRadius. La taille de chaque cluster est proportionnelle au nombre de points au sein du cluster et suit le Smart Mapping, c'est à dire que automatiquement, en fonction du nombre de clusters sur toute l'étendue de la carte, et des points contenus en eux, à chaque échelle nous aurons automatiquement une nouvelle taille définie pour visualiser plus facilement la carte. Le clustering fonctionne pour les FeatureLayer, CSVLayer et GeoJSONLayer. Et ne fonctionne pas encore en 3D.
Le clustering ne fonctionne que sur les couches contenant des Point dans un MapView avec une symbologie de type SimpleRenderer, UniqueValueRenderer, et ClassBreaksRenderer. Nous allons voir dans la suite de l'article comment appliquer le clustering avec une symbologie de type UniqueValueRenderer (pour un attribut donné, chaque valeur a sa propre symbologie, utile pour les attributs qualitatifs).
Le clustering ne s'applique donc pas aux couches de polyligne et polygone.
Cette méthode est indépendante du Renderer.
Pour quel besoin ?
Le clustering permet donc d'agréger, selon un rayon de pixels défini, des entités d'une même couche de points. Par exemple dans cet exemple il agrège les centrales dans un rayon de 40 pixels. Ici un point représente toutes les centrales dans un rayon de 40 pixels et la couleur de ce point dépend du type majoritaire de centrales qu'il contient. Lorsque la variation de taille n'est pas définie dans le renderer, plus il y a d'entités dans ce cluster, plus il sera gros. Ainsi lorsqu'on zoome de plus en plus, les clusters se défont et lorsqu'on dézoome ils se font de plus en plus. Gardez à l'esprit que le point représentant un cluster n'est pas forcément placé sur une centrale existante.
Comment le créer ?
Cette méthode s'applique donc aux couches et n'a pas besoin d'être chargée dans le require grâce à l'autocasting, on applique directement la méthode featureReduction à la couche :
layer.featureReduction = {
type: "cluster",
clusterRadius: "120px",
popupTemplate: {
content: "This cluster represents {cluster_count} features.",
fieldInfos: [{
fieldName: "cluster_count",
format: {
digitSeparator: true,
places: 0
}
}]
}
};
Le clusterRadius définit le rayon en points (ou pixels si spécifié) de chaque zone dans laquelle plusieurs points seront regroupés et visualisés comme un seul cluster. Sa valeur par défaut est 80.
La diminution du rayon du cluster crée plus de clusters généralement composés d'un nombre moindre d'entités.
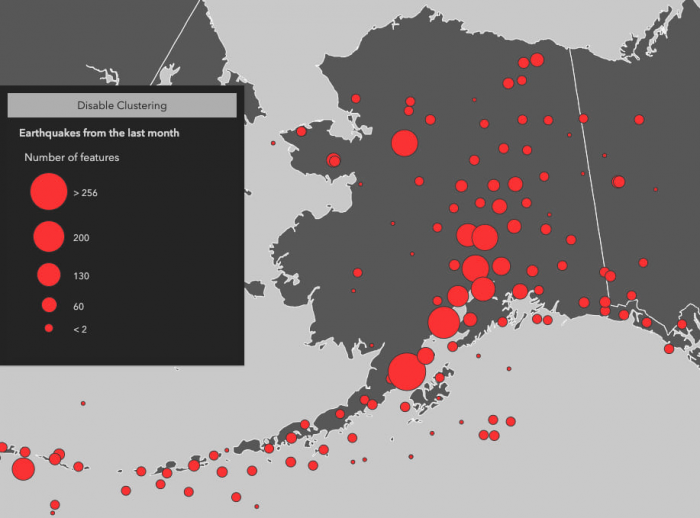
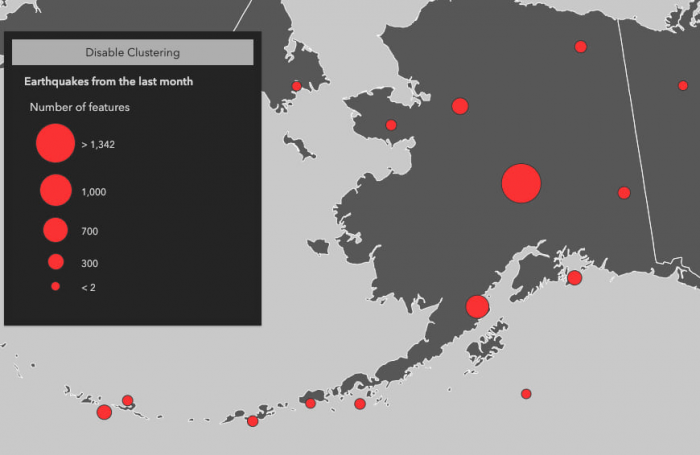
Avec popupTemplate vous pouvez configurez la fenêtre à afficher lorsque vous cliquez sur un cluster, et choisir d'y afficher la valeur de cluster_count qui est créée pour chaque cluster automatiquement et dynamiquement et donne le nombre d'entités au sein du cluster.
Styles et configurations
Le rendu contrôle le style d'un calque, même lorsqu'il est groupé. Le contenu suivant décrit les différentes manières dont le rendu affecte le style et la fenêtre contextuelle d'un calque en cluster.
Selon le nombre seulement
Dans le scénario le plus élémentaire, où tous les points sont stylisés avec un SimpleRenderer et aucune variable visuelle, le nombre d'entités au sein du cluster déterminera la taille du cluster.
Voici un exemple de code reprenant ce qu'on a dit précédemment :
// Configures clustering on the layer. A cluster radius
// of 100px indicates an area comprising screen space 100px
// in length from the center of the cluster
const clusterConfig = {
type: "cluster",
clusterRadius: "100px",
// {cluster_count} is an aggregate field containing
// the number of features comprised by the cluster
popupTemplate: {
content: "This cluster represents {cluster_count} earthquakes."
}
};
const layer = new GeoJSONLayer({
title: "Earthquakes from the last month",
url: "https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_month.geojson",
copyright: "USGS Earthquakes",
featureReduction: clusterConfig,
// popupTemplates can still be viewed on
// individual features
popupTemplate: {
title: "Earthquake Info",
content: "Magnitude {mag} {type} hit {place} on {time}"
},
renderer: {
type: "simple",
field: "mag",
symbol: {
type: "simple-marker",
size: 4,
color: "#fc3232",
outline: {
color: [50, 50, 50]
}
}
}
});
Visual variables et class breaks
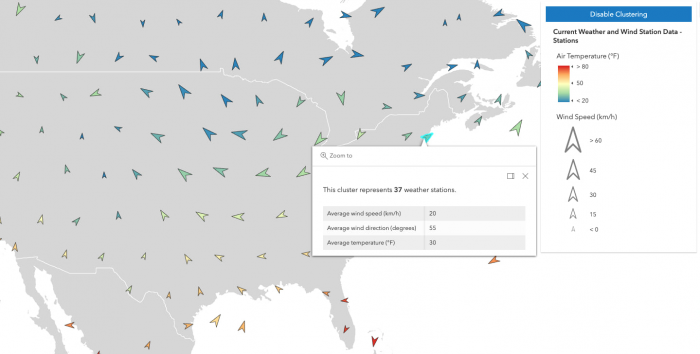
Lorsqu'un champ numérique est utilisé par le rendu, avec une ou plusieurs variables visuelles ou un ClassBreaksRenderer, la valeur moyenne de ce champ sera utilisée dans la symbologie de cluster et mise à la disposition du développeur dans le popupTemplate.
Dans l'exemple ci-dessous, la couche représentant les stations météorologiques est rendue avec trois variables visuelles: couleur, taille et rotation. Lorsque le clustering est activé, la moyenne de chaque champ référencé dans les variables visuelles est calculée pour les entités de chaque cluster. La couleur, la rotation et la taille du cluster sont ensuite appliquées au graphique du cluster en fonction de la valeur moyenne de chaque champ respectif pour les variables visuelles des entités de ce cluster.
Voici un exemple de code :
// Displays each weather station with three variables:
// Rotation - indicates wind direction
// Color - indicates air temperature
// Size - indicates wind speed
const renderer = {
type: "simple",
symbol: {
type: "simple-marker",
// Arrow marker
path: "M14.5,29 23.5,0 14.5,9 5.5,0z",
color: [50, 50, 50],
outline: {
color: [0, 0, 0, 0.7],
width: 0.5
},
angle: 180,
size: 15
},
visualVariables: [{
type: "rotation",
// Use {cluster_avg_WIND_DIRECT} in the
// featureReduction.popupTemplate to
// display the average temperature of all
// features within the cluster
field: "WIND_DIRECT",
rotationType: "geographic"
},
{
type: "size",
// Use {cluster_avg_WIND_SPEED} in the
// featureReduction.popupTemplate to
// display the average temperature of all
// features within the cluster
field: "WIND_SPEED",
minDataValue: 0,
maxDataValue: 60,
minSize: 8,
maxSize: 40
},
{
type: "color",
// Use {cluster_avg_TEMP} in the
// featureReduction.popupTemplate to
// display the average temperature of all
// features within the cluster
field: "TEMP",
stops: [{
value: 20,
color: "#2b83ba"
},
{
value: 35,
color: "#abdda4"
},
{
value: 50,
color: "#ffffbf"
},
{
value: 65,
color: "#fdae61"
},
{
value: 80,
color: "#d7191c"
}
]
}
]
};
// Configures clustering on the layer including
// a popupTemplate referring to aggregate fields
// that summarize the values of the fields used
// to render the cluster graphics.
const clusterConfig = {
type: "cluster",
popupTemplate: {
content: [{
type: "text",
text: "This cluster represents <b>{cluster_count}</b> weather stations."
},
{
type: "fields",
fieldInfos: [{
fieldName: "cluster_avg_WIND_SPEED",
label: "Average wind speed (km/h)",
format: {
places: 0
}
},
{
fieldName: "cluster_avg_WIND_DIRECT",
label: "Average wind direction (degrees)",
format: {
places: 0
}
},
{
fieldName: "cluster_avg_TEMP",
label: "Average temperature (°F)",
format: {
places: 0
}
}
]
}
]
}
};
const layer = new FeatureLayer({
portalItem: {
id: "cb1886ff0a9d4156ba4d2fadd7e8a139"
},
renderer: renderer,
featureReduction: clusterConfig
});
Valeurs uniques
Lorsqu'une couche contient un UniqueValueRenderer, les graphiques en cluster sont donc rendus avec le symbole de la valeur unique la plus courante des entités représentées par le cluster. Avec cette symbologie vous pouvez appliquer comme symbole vos propres images hébergées pour chaque valeur attributaire comme celle-ci par exemple :
Vous pouvez alors en définissant le renderer, choisir le type de symbologie désiré. Puis vous choisissez pour quel attribut elle s'applique, enfin pour chaque valeur de l'attribut vous spécifiez la symbologie correspondante, donc ici un firefly différent selon la classification qu'on peut trouver ici :

C'est ce que j'ai appliqué dans mon application, vous pouvez retrouver le code ici sur mon github.
Une autre méthode, si vous disposez d'un compte ArcGIS Online, serait de directement créer votre carte dans la visionneuse de cartes ArcGIS Online et de choisir la symbologie firefly la bas puis de charger la WebMap à l'aide de la classe WebMap au sein de votre application pour bénéficier de la même façon du clustering.
Popup templates
Vous pouvez également configurer un popupTemplate dans FeatureReductionCluster. Cela permet à l'utilisateur d'afficher des informations récapitulatives sur les fonctionnalités représentées par le cluster. Ceci est indépendant du layer.popupTemplate, qui affichera des informations sur les entités individuelles non groupées. Le featureReduction.popupTemplate vous donne accès aux champs d'agrégation utilisés pour résumer les fonctionnalités au sein du cluster.
Le tableau ci-dessous décrit les champs d'agrégation que vous pouvez référencer dans la fenêtre contextuelle du cluster.
| Field Name | Description |
cluster_count | Le nombre d'entités dans le cluster. Ce champ est toujours disponible sur les couches groupées. |
cluster_avg_{fieldName} | Uniquement disponible dans les couches groupés avec des rendus visualisant au moins un champ numérique de taille, d'opacité, de rotation, de couleur continue ou class breaks. Ce champ décrit la moyenne de chaque champ numérique rendu parmi toutes les entités du cluster. |
cluster_type_{fieldName} | Uniquement disponible dans les couches en cluster avec un UniqueValueRenderer. Ce champ décrit la valeur prédominante du champ rendu parmi toutes les entités du cluster. |
layer.featureReduction = {
type: "cluster",
popupTemplate: {
content: popupTemplate: {
content: "This cluster represents {cluster_count} earthquakes."
}
};Slider de valeurs pour filtrer côté client
Dans notre cas, on visualise des clusters de centrales. Donc toutes les centrales dans une certaine zone d'influence sont regroupés en 1 cluster qui prend la couleur du type de centrale dominante en terme de nombre dans le cluster. On constate en France beaucoup de cluster de centrales éoliens. Et en effet, lorsqu'on désactive le clustering, la proportion de points verts en France est très importante.
Mais il faut aussi noter que pour notre méthode de clustering, une centrale nucléaire à 2000 MW est équivalente à une seule éolien à 1 MW. Donc si on a 3 centrales très rapproches dont 2 éoliens à 1 MW et une nucléaire à 2000 MW, le cluster de ces 3 centrales sera de couleur verte signifiant que l'éolien est prédominant ici. Il peut alors être pertinent d'ajouter un filtre sur les valeurs attributaires que nous souhaitons voir pour améliorer notre analyse cartographique.
On peut alors ajouter un slider, on va pouvoir filtrer côté client, sans avoir besoin de requêter, pour ne garder que les centrales dépassant une certaine production de MW pour par exemple garder que les centrales nucléaires, à gaz & pétrole pouvant atteindre de grosses productions.
Comment le définir ? C'est très simple :
On définit le widget Slider avec la valeur minimum et maximum puis la valeur par défaut. Puis on configure l'événement en écoutant le slider, dès qu'on change la valeur du slider alors on filtre la couche sur les valeurs supérieurs ou égales de la capacité en mégawatt choisie :
const slider = new Slider({
min: 0,
max: 2000,
values: [0],
container: document.getElementById("sliderDiv"),
rangeLabelsVisible: true,
precision: 0
});
const sliderValue = document.getElementById("sliderValue");
slider.on(["thumb-change", "thumb-drag"], function(event) {
sliderValue.innerText = event.value;
layerView.filter = {
where: "capacity_mw" + " >= " + event.value
};
});Bientôt disponible
N'oubliez pas, le clustering est en version bêta! N'hésitez pas à apporter des commentaires sur les améliorations apportées à cette dernière implémentation.
Certaines choses non prises en charges en charge actuellement, mais qui devraient arriver bientôt :
- Expressions d'arcade - Prise en charge des couches avec des rendus contenant au moins une valueExpression (c'est-à-dire l'expression d'arcade) dans le rendu ou la variable visuelle. Cela inclut les rendus de prédominance, de relation et d'âge créés à partir des méthodes de smart mapping.
-Étiquettes - Actuellement, les clusters ne peuvent pas être étiquetés avec le nombre total d'entités composant le cluster ni aucune autre information agrégée connue par le cluster. Modèles popup générés automatiquement
- Le popupTemplate n'est pas généré par défaut (c'est la valeur par défaut dans 3.x). Esri travaille sur l'ajout de fonctions d'assistance pour créer de bons modèles contextuels par défaut pour les couches en cluster.
- Prise en charge complète des références spatiales. Le regroupement des couches avec des références spatiales autres que Web Mercator et WGS 84 est expérimental et peut ne pas fonctionner pour chaque projection. L'idée est de stabiliser le support de toutes les références spatiales.
Merci d'avoir lu! Assurez-vous d'explorer les échantillons et essayez de clusteriser vos propres couches.
Vous pouvez vous abonner à ce blog pour lire d'autres articles sur le développement Web d'applications cartographiques et découvrir comment notre API est une superbe alternative à Google Maps !
Vous voulez vous aussi réaliser des applications Web cartographiques et dynamiques ? N'hésitez pas à souscrire à un plan gratuit ArcGIS for Developers pour développer vos propres applications cartographiques 2D ou 3D ! Cet article résume ce que vous obtiendrez. Et pour en savoir sur l'API c'est ici.





{kind=link}
Aucun commentaire:
Enregistrer un commentaire